Community engagement platform requirements
What private-sector planning firms need from community engagement software

The category called "community engagement software" doesn't actually exist as a single market. It's two categories that have been collapsed into one. The first was built for municipalities and government agencies running long-term engagement programmes. The second was built for the consulting firms that deliver engagement as part of project contracts. The operating models are different, the procurement contexts are different, and the pain points are different. Private-sector planning, design, and engineering consultancies should evaluate platforms against the second category, and most generic comparisons mix the two. This guide explains why, what the right criteria are, and what to ignore.
Why two categories got collapsed into one
Most engagement platforms in the US market started by selling into government — municipalities, transit agencies, regional planning organisations, DOTs. The buyer profile favoured long-term contracts. The platform features grew around that operating model: one engagement programme inside one organisation, run by a small in-house team, evaluated through procurement cycles that prized institutional credibility. When consulting firms started running digital engagement on those same platforms, the fit was approximate at best. The platforms still got bought because there wasn't an alternative.
That history shapes how the category is described today. "Community engagement platforms" reads as one market because the platforms are described in language that flattens the difference. What gets obscured is the operating model split. A municipality runs one engagement programme inside one organisation over many years. A consulting firm runs fifteen projects across multiple offices under fixed-fee contracts with irregular pipelines. The same software cannot optimise for both at once.
When a planning firm evaluates a platform built for the government buyer, the firm is buying a tool whose design choices optimise for someone else's operating model. The friction shows up later. Per-project user assignment that scales badly with project count. Pricing models that punish irregular pipelines. Analysis workflows that assume an institutional team rather than a fixed-fee project manager. Reporting layers that produce data exports rather than client-ready deliverables.
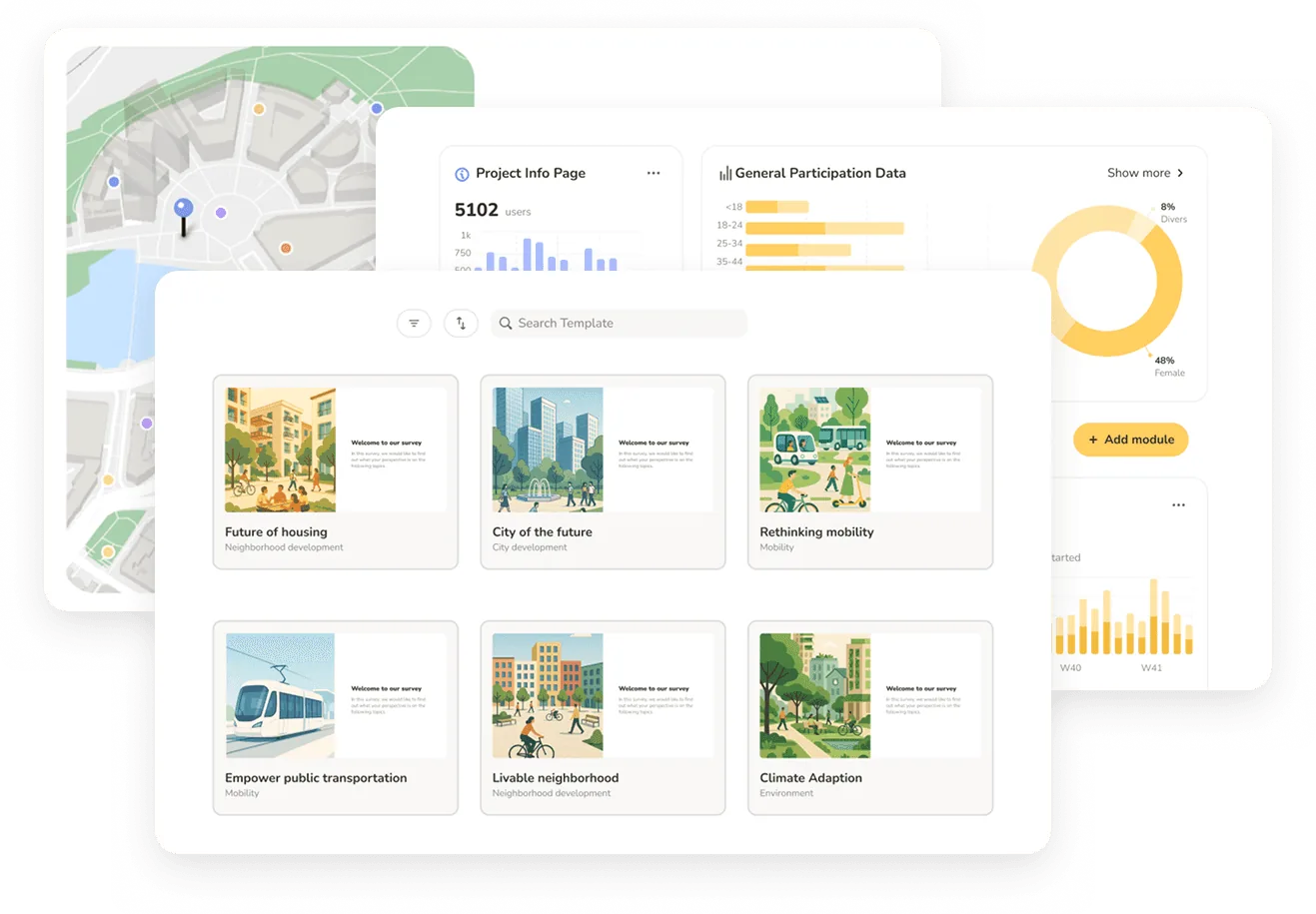
Naming the two categories cleanly is the first step toward evaluating against the right one. Government engagement platforms include Social Pinpoint, Go Vocal (formerly CitizenLab), PublicInput, EngagementHQ/Bang the Table, and MetroQuest. Consulting workflow platforms are a smaller and newer category. Senf is built for this operating model. Maptionnaire occupies a narrower position inside it — strong on spatial surveys, lighter on the rest of the workflow. The category guide makes the structural argument; the dedicated comparison articles name the specific trade-offs.
The criteria that matter
The seven criteria below assume the consulting workflow operating model. They're framed for firms running project-based work on fixed-fee contracts, not for institutional buyers running ongoing engagement programmes.
1. Spatial input the team can actually configure
Map-based feedback is table stakes for transportation, mobility, land development, and urban planning work — corridor studies, station areas, parks, public space redesigns. The question isn't "does the platform have maps." Every credible platform in this category does. The question is whether the team running the engagement can configure spatial questions without a GIS specialist.
The evaluation moves: ask to set up a map question yourself during the demo, not just watch the vendor do it. Ask how a project manager without ArcGIS experience would configure the same question on a different project. Test whether the platform's spatial input degrades to a non-spatial fallback (PDF survey, plain-text question) for rural respondents without internet access.
Sophisticated map configuration that requires GIS expertise is a real capability, but it concentrates the engagement work on one person. Spatial input usable by the broader team distributes that work across project managers. The criterion to evaluate against is the second model, not the first.
2. Analysis that's native to the workflow, not bolted on
Most consulting firms running digital engagement have built an Excel-plus-AI workaround. Export comments from the engagement platform, paste into Excel, prompt Claude or ChatGPT to categorise, paste the categories back in for the report. Two of seven recent sales prospects we spoke to were running exactly this stack. The workaround works. It also costs hours per project and introduces errors at every paste step.
The criterion isn't whether the platform has AI features. Most platforms now claim AI in some form. The criterion is whether AI categorisation, sentiment analysis, and theme extraction run on the comment data inside the platform and feed directly into the reporting layer, or whether they sit alongside the workflow as an additional step the team has to manage.
The evaluation moves: ask to see analysis run on a real comment set during the demo, ideally one the firm provides rather than one the vendor pre-loads. Ask whether the AI output is exportable as a categorised dataset or as a draft of the actual deliverable. The gap between those two outputs is the gap that determines whether the workflow stays in the platform or gets exported back to Excel.
3. Pricing model that fits irregular project pipelines
The consulting-firm pipeline isn't predictable. Some quarters bring small studies, others bring large comprehensive plans, others bring nothing for two months and then a federal grant cycle that needs three projects spun up at once.
Three pricing model shapes are common in this category. Per-project allotment (Social Pinpoint's model) charges for a fixed number of projects against an annual contract; firms underuse or overspend depending on pipeline volatility. Hybrid subscription-plus-per-survey (Maptionnaire's model) charges per survey on top of a base subscription; firms with portfolios of small surveys accumulate variable costs on both axes. Annual unlimited (Senf's annual licence) or project licence (Senf's other option) fixes the cost regardless of project count, or fixes the cost for one project with everything inside it unlimited.
The evaluation move is mechanical: model the platform cost against the firm's actual project mix over the last twelve months. The cheapest sticker price isn't always the lowest total. A per-survey model can be cheaper for a firm running few large surveys and more expensive for a firm running portfolios of small ones. The model that fits the pipeline matters more than the headline number.
4. Client-ready output, not raw data
Deliverables go to clients and public agencies, not just internal teams. The criterion is whether the platform produces structured output suitable for client review, or only raw exports the firm has to assemble into a deliverable.
The practical test: ask to see the platform's reporting layer. If the output is a CSV that needs to be charted in Excel and assembled in PowerPoint, the firm is still doing the deliverable work the platform should have done. If the output is a dashboard or report draft the firm refines rather than builds from scratch, the platform is doing its job.
This criterion compounds with Criterion 2. AI analysis that produces a categorised dataset is half the work. AI analysis that produces a draft of the actual deliverable is the work consulting firms are actually paying for.
5. Hybrid participation feeding one dataset
In-person and digital engagement need to feed into the same data structure. Federal program requirements (SS4A, NEPA documentation), rural connectivity gaps, and demographic equity expectations all push firms toward hybrid engagement. Public meetings still happen. So do open houses, charrettes, and pop-up tabling at community events.
The evaluation moves: ask how QR-code input from an in-person event lands in the same project as online responses. Ask whether printed survey forms can be transcribed back into the platform without manual re-entry. Ask whether the engagement output reflects both channels in one set of charts or whether the team still has to merge the data manually at the reporting stage.
The platform that requires the firm to maintain two parallel datasets and merge them at the end creates a documentation problem at the reporting stage. The criterion is one unified dataset across channels.
6. Documentation defensibility for procurement and regulatory review
NEPA and state-level participation requirements demand documented, traceable processes. SS4A engagement plans, comprehensive plan public involvement records, and entitlement-review documentation all share a structural requirement: every submission accounted for, every channel logged, every demographic represented.
This is also where accessibility belongs in the evaluation. WCAG compliance, multilingual support, demographic reach, screen-reader compatibility. These show up as procurement requirements in real RFPs and as defensibility concerns in real planning commission reviews. A firm cannot defend engagement that excluded the community members the project most needed to hear from.
The evaluation move: ask the platform to produce a documentation export for a sample project. Look at what's included — engagement timeline, channels used, participation by demographic, response handling, accessibility provisions. The export is the artefact that defends the firm's process in front of a planning commission or federal program reviewer. Bohler Engineering uses this kind of structured documentation across 43 US offices for entitlement review. The criterion is whether the platform produces an audit trail the firm can defend without manual reconstruction.
7. Workflow fit for the consulting operating model
The integrating criterion. The platform either fits the operating model of project-based work, distributed teams, irregular pipelines, and fixed-fee constraints, or it doesn't. The previous six criteria are specific tests; this one is the structural question.
The evaluation move is direct. Ask the platform vendor to walk through how the platform would handle the firm's actual project portfolio. Three concurrent projects in different verticals. Two project managers cycling on and off engagements as work comes in. A federal grant cycle that requires three project setups in two weeks. A project that ships its engagement deliverable into the client's planning commission package.
If the vendor's answer requires workarounds, change management training, or additional licensing tiers for each of those scenarios, the platform is built for a different operating model. If the answer is straightforward and the platform handles each scenario natively, the platform fits.
What to ignore
Four evaluation criteria that appear in generic platform comparisons but actively mislead consulting firms making this decision.
Number of features listed on the vendor's website.Generic feature counts don't correlate with workflow fit. A platform with thirty modules built around a different operating model is harder to use than a platform with seven built around yours. Count the features that map to the firm's actual project types, not the features that exist.
Whether the platform is "the most established" in the market.In community engagement software, the most established platforms are the ones with the longest history selling into municipal procurement. That track record is real, but it's a signal about government suitability, not consulting fit. Established correlates with institutional credibility for the buyer, not with workflow fit for the consultancy.
How the platform looks in a 30-minute demo.Most platforms demo well in 30 minutes. The configuration is pre-built, the data is curated, the workflow shows the happy path. The test that matters is how the platform behaves on the firm's actual third project of the year, run by the second project manager to use it, under fixed-fee constraints. Demo polish is a weak proxy for workflow durability.
How easy the maps are for a GIS expert to configure — versus how easy they are for the broader team to use.A platform with deep map configuration that requires GIS expertise to set up is a different product from a platform that produces strong spatial input with template-driven configuration by a non-GIS user. Both are valid choices, but they fit different operating models. Evaluate the map experience for the person who'll actually be running it on this project, not the most technically fluent person in the firm.
How to evaluate platforms against these criteria
Three practical moves that turn the criteria into a buyer's protocol.
Run the demo against an actual RFP.Generic vendor demos don't reveal workflow fit. Ask each vendor to configure the platform against an RFP the firm has actually responded to. The platform that handles the real scope without workarounds is the platform that fits. The platform that requires the vendor to explain why certain features aren't quite ready for this scope is the platform that won't fit later either.
Model the pricing against twelve months of real project history.Sticker price comparisons mislead. Model each platform's cost structure against the firm's actual project mix from the last twelve months. The cheapest sticker can be the most expensive total, and the most expensive sticker can be the cheapest total. The right answer depends on the firm's pipeline, not on the vendor's preferred narrative about pricing.
Talk to consulting firms running the platform, not municipal customers.Reference calls with municipal users tell you whether the platform works for municipalities. They don't tell you whether the platform works for consulting workflows. Ask each vendor for two consulting-firm references who run engagement at scale, with project counts and operating shapes comparable to the firm's own. If the vendor can't provide them, that itself is signal.
Frequently asked
Is community engagement software different from survey software?
Yes, structurally. Survey software (SurveyMonkey, Google Forms, Qualtrics) is built for general feedback collection across any context. Community engagement software adds spatial input, public-process documentation, hybrid participation, and reporting structured for planning deliverables. The categories overlap at the survey layer but diverge everywhere else.
Do we need a community engagement platform if we already have ArcGIS and SurveyMonkey?
The consolidation case depends on the firm's project volume and the analysis workload. For a firm running occasional small engagement on top of GIS work, the existing stack may be fine. For a firm running multiple projects per quarter with substantial open-text comment volumes, the analysis time saved by a consolidated platform compounds quickly. The decision point is usually the third or fourth project of the year, when the patchwork starts breaking.
How do we know if a platform is built for government or consulting?
Three practical heuristics. Pricing structure that assumes one buyer with a long-term contract suggests government orientation; pricing structured around projects or annual unlimited suggests consulting orientation. User access models that scale with named users at one organisation suggest government; team access that scales with project count suggests consulting. Reference customer lists weighted toward municipalities and agencies suggest government; lists weighted toward consulting firms suggest consulting.
What's the difference between Social Pinpoint, Maptionnaire, and Senf?
Short answer: Social Pinpoint is built for the government buyer; Maptionnaire is a spatial survey platform with GIS heritage that consulting firms can use but that tilts toward technical operators; Senf is a consulting workflow platform that includes spatial surveys plus AI analysis, client-ready reporting, and templates for common project types. The dedicated comparison articles cover each in detail — see the Social Pinpoint comparison and the Maptionnaire comparison linked below.
Are there community engagement platforms built specifically for our vertical?
Not really. The platforms in this category serve multiple verticals (transportation, urban planning, landscape, land development) because the buyer base in any single vertical isn't large enough to support vertical-specific software. The right question is whether the platform's templates and module set fit the project types the firm actually runs. Senf includes templates for transportation corridor studies, comprehensive plans, master plans, and public space redesigns; firms working primarily in one vertical should evaluate template fit alongside the seven criteria above.
The two-category split is the analytical move that makes the rest of platform evaluation tractable. Once a firm decides it's buying consulting workflow software, not government engagement software, the criteria narrow and the comparison set narrows with them. The platforms that win are the ones that fit how the firm actually operates — not the ones that look best in a 30-minute demo.
See Senf in action
• Walk through a project scenario relevant to you
• See setup, engagement, and analysis end to end
• Discuss pricing based on your project volume
See Senf in action
• Walk through a project scenario relevant to you
• See setup, engagement, and analysis end to end
• Discuss pricing based on your project volume
See Senf in action
• Walk through a project scenario relevant to you
• See setup, engagement, and analysis end to end
• Discuss pricing based on your project volume